
Šta je SERP?
Search Engine Result Page je stranica pretraživača sa rezultatima pretraživanja tj. pozicijama koju stranica ima u rezultatima pretrage za traženu reč/frazu. To isključuje plaćene pozicije pri vrhu liste rezultata svakog pretrazivača. Cilj je pozicionirati sajt na prvoj stranici rezultata pretraživanja, po mogućnosti što više pri vrhu rezultata pretraživanja. Statistike pokazuju da preko 90 odsto korisnika pretraživača ne idu dalje od prve stranice pretraživanja.
Šta je PR i kako ga povećati?
PageRank je Google-ova patentirana tehnologija koja pokazuje popularnost web stranice, a ne web sajta u celosti kako se pogrešno misli. Da bi web stranica dobila PR potrebno je da neka druga strana linkuje ka njoj i na taj način joj “prenosi” deo svog PR-a. Svi spoljni linkovi jedne stranice (outbound links) dele PR, tako da za maksimalne rezultate treba težiti ka tome da se postavi link na stranici sa visokim PR-om i malim brojem izlaznih (spoljnih) linkova. Mnostvo izlaznih linkova obara PageRank. Što se tiče broja dolazećih linkova, što ih je više, to je bolje. I još nešto govori algoritam: nepostajanje dolazećih linkova može da ima negativan uticaj na PR koeficijent stranice na koju se ukazuje (najgori slučaj je da nema nikakav uticaj).
PR su u originalu formulisali Sergey Brin i Larry Page u svom radu The Anatomy of a Large-Scale Hypertextual
Web Search Engine. Zasnovan je na premisi da u akademskom svetu značaj istraživačkog rada se procenjuje na osnovu broja citata koje rad ima u drugim istraživačkim radovima.
Sergey Brin i Larry Page su kao prvu verzija internet pretraživača razvili BackRub. Ta verzija ocenjena je vrlo pohvalno od kolega sa univerziteta i pozitivne kritike počele su da cirkulišu internetom. S obzirom na to da su kuburili sa novcem, Lari je potreban hardver sklapao od jeftinih komponenti (prvi štampač imao je kućište od Lego kockica). S obzirom na sve veći broj web stranica koje su smeštali u svoju bazu podataka i sve širi krug korisnika, Sergej i Lari nikad nisu imali dovoljno računara i prateće opreme.
PR ne raste linearno, to je logaritamska funkcija. (Zato su vrednosti PR1-PR10). Zato je neuporedivo lakše stići od PR1 do PR6 nego od PR6 do PR7. PR koji vidimo na Google Toolbaru za IE, ili PageRank Status ekstenziji za FireFox je samo aproksimacija prave vrednosti koja čak i ne mora biti tačna, jer se Toolbar PR ne update-uje redovno. Zato ga ne treba prihvatati kao relevantnog.
Najčešća zabluda vezana za PR jeste da on direktno utiče na rangiranje web strane u pretragama. Ta zabluda nagoni mnoge webmastere da usmere svu energiju u povećanje PR-a u želji da se što bolje rangiraju. Nažalost, PR je samo jedan od faktora koji utiču na SERP-ove Googla. Drugi aspekti se određuju na osnovu algoritma za rangiranje stranica. Taj algoritam se neprekidno menja, ali dole niže će biti navedeni parametri (šabloni optimizacije) koji utiču na taj algoritam.
Vremenom su se SEO kompanije izveštile u povećanju PageRanka na načine koji već počinju da dovode u pitanje vrednost ove tehnike, te ju je Google u jednom od svojih patenata dodatno rafinirao. Naime, inicijalno dobijeni rezultati pretrage sada se dodatno vrednuju na osnovu njihove međusobne povezanosti, to jest dokumenti iz prvobitnog seta rezultata dobijaju na vrednosti ukoliko drugi dokumenti iz istog seta imaju link na njih.
Možda je preciznije reći da PR algoritam se primenjuje na rezultate Google pretrage nakon što se obave druga izračunavanja. Google algoritam najpre izračuna relevantnost stranica iz svog indeksa u odnosu na pojmove koji se koriste prilikom pretrage, potom relevantnost množi sa PR koeficijentom kako bi se dobila konačna lista. Dakle, ako je veća vrednost PR koeficijenta, stranica će biti na boljem mestu u okviru rezultata, ali još uvek postoje brojni drugi faktori koji se razmatraju, a koji su obično vezani za pozicionoranje ključnih reči na Web stranici.
PageRank kalkulator kreira model Web prezentacije u malom, definiše linkove među stranicama i razmatra uticaj modela na raspodelu PR koeficijenta stranica.
Šta je SEO i koliko je važana za Web dizajnera?
SEO (Search Engine Optimization) = optimizacija sajta prema zahtevima pretraživača. Deo strategija marketinga putem pretraživača koji se odnosi na tehnike prilagođavanja samog sajta zahtevima pretraživača sa aspekta kvalitetnog pozicioniranja sajta u prirodnim rezultatima pretraživanja, za određene ključne reči. No, najbolji način da se optimizuje Web sadržaj za pretraživače je da se optimizuje za korisnike. Primetno je da Web dizajneri posežu za SEO trikovima kako bi uticali na rang preyentacije bez da ulože vreme u poboljšanje kvaliteta sopstvenog sajta i sadržaja koji na njemu nude. Kvalitetan sadržaj koji je likovan sa strane sa velikim PR-om, tako sto se pruži nešto što drugi Web dizajneri smatraju dovoljno vrednim da linkuju i nema brige.
Šta je Sandbox?
Sandbox je filter koji Google primenjuje na novim i ostalim stranicama. On pogađa sve sajtove, bez izuzetka najvise 30-40 dana po prvom indeksiranju i traje 60-90 dana, zavisno o temi sitea, komercijalni sajtovi su najduže u sandboxu, sajtovi koji ciljaju vrlo komercijalne pojmove, vrlo tražene pojmove takođe su duže unutar sandbox-a. Rezultat ovog filtera je da sajt ne dobija punu vrednost od svojih ulaznih linkova i sadržaja i samim tim se kotira niže (pa čak i potpuno ispada iz pretrage). Razlog za postojanje ovog filtera je sprečavanje zloupotreba – zahvaljujući njemu Google ima dovoljno vremena da otkrije problematične sajtove i ne dozvoli im da se kotiraju visoko. Mana: sandbox nema mogućnost otkrivanja problematičnih sajtova niti baniranja, već samo sprečavanje postizanje visokog rejtinga preko noći i bombardovanja od strane spammera, ali na žalost ima ulogu da webmasteri koriste što više adwords servis.
Posledice na PR stranice koja se nasla u sandbox-u: inicajlizuje sa pr0, dosta se penalizuje stranica u pretrazi (trajanje penala 180 dana i vise)
Jedna od glavnih tendencija koja se može videti iz Googleovih patenata jeste borba protiv „search engine spama”, to jest protiv sajtova koji se korišćenjem neetičkih metoda optimizacije za pretraživače rangiraju bolje nego što to njihov sadržaj zaslužuje. Naime, u patentima se otkriva da se velika pažnja kod kreiranja rezultata pretrage i uopšte rangiranja sajta na pretraživaču poklanja istorijskim podacima sa sajta. Pod „istorijskim” podacima podrazumeva se niz faktora čije promene Google prati na sajtu tokom vremena. Na primer:
• Konstantnost tematike – sajtovi koji dugo obrađuju jednu ili više tema, a onda naglo promene svoju oblast, rizikuju da im rangiranje opadne.
• Dinamika dodavanja novih sadržaja – koliko se često sajt osvežava novim sadržajima ili koliko se često stari sadržaji značajno menjaju.
• Dinamika promena sidra (anchor – sidro, tekst u linku na neku stranicu)
• Dinamika promene gustine ključnih reči na stranicama
• Procenat klikova na link na sajt koji je prikazan u rezultatima pretrage (Google ipak prati klikove kod rezultata pretrage, iako je bilo puno dvoumljenja oko toga treba li ih pratiti ili ne, tzv. LOG analiza i veštačka inteligencija na klik, sve prisutnija tehnika u reformulaciji upita i proceni sličnosti dva upita kod npr. FAQ sistema.)
• Dinamika promene broja linkova
Nagla promena svakog od ovih faktora obaveštava Google da se na sajtu nešto neobično događa i sajt rizikuje da bude izbačen iz rezultata pretrage.
Iz objavljenih patenata vezanih za algoritme pretrage se mogu videti detalji tehnologija koje Google koristi ili namerava da koristi za svoje pretrage.
Tako se saznaje da Google prati i neke stvari za koje to nikada ne bismo pretpostavili kao što su dužina registracije domena (što duže to bolje – znači da vlasnik domena ima ozbiljne namere za rayliku od spamera), stabilnost i regularnost hosta (ukoliko vaš sajt deli host sa spamerskim sajtovima, penalizuje se, kažnjava PRi), potpunost podataka vezanih za domen u WHOIS bazi i to koliko se ti podaci često menjaju. Takođe, ono što se borcima za privatnost svakako neće dopasti jeste to što se prate i određeni privatni podaci korisnika Googlea kao što su favorites liste, bookmarks, privremeni (temp) fajlovi i keširane stranice. Veliko je pitanje kako Google ovo prati: da li koristi neki poseban spyware ili i sam Google toolbar prati date parametre (tokom instalacije toolbara korisnik se pita da li želi napredne mogućnosti koje ujedno šalju i neke podatke Googleu.).
Naravno, Google nigde ne pominje koje su od pomenutih tehnika implementirane, a koje se samo planiraju za budućnost. U svakom slučaju, patenti su dobar način da se preduhitri konkurencija sa određenim idejama i da se korisnici ubede u posvećenost Googlea unapređivanju tehnika pretrage. Lepo je videti da, uprkos upornom nastojanju spemera da svoje sajtove postave tamo gde im nije mesto, Google ipak radi na tome da sadržaj bude ono što određuje položaj sajta na pretraživaču
KLJUČNE REČI - ULOGA
Contextual Advertising (Keyword Advertising) – Tehnike ostvarivanja vidljivosti Web sajta (povećanje broja posetilaca sajta) zakupom ciljanih ključnih reči i oglašavanjem na Web stranicama koje su u kontekstu tih zakupljenih ključnih reči. Pretraživači putem posebnog programa određuju koju će reklamu pustiti na određenoj stranici, u zavisnosti od frekvencije pojavljivanja ključnih reči (Keyword Density) posmatrane stranice.
Šta je keyword density?
Jedan od najbitnijih parametara za rangiranje je odnos sadržaja i ključnih reči. Keyword density je prosto rečeno odnos pojavljivanja ključne fraze u pretrazi i ukupnog teksta na stranici i izražava se u procentima.
Koliko ključnih reči je dovoljno? Ne zna se precizno. Ono sto je sigurno jeste da 3% - 6% neće škoditi, sve preko toga je manji ili veći rizik da pretrazivač okarakteriše Web stranicu kao spam. Savet: analizirati ključne reči drugih sajtova, proveriti njihov density, podizati lagano za 1% i posmatrati rezultate.
Kako odabrati dovoljno preciznu ključnu reč? Ovo je zapravo najteži deo SEO posla. Ideja vodilja treba da bude fraza koja se puno traži, a ima malo rezultata pretrage. Postoji dosta alata za proveru, tzv “keyword suggestion tool”, a verovatno najpoznatiji je http://www.digitalpoint.com, koji kombinuje Overture i Wordtracker. Uz pomoć ovih alata zanimljivo je uporediti broj dnevnih pretraga za ciljne fraze sa brojem rezultata koje Google (i ostali pretrazivači) daju za te fraze.
Mnogi Web autori se trude da dovode posetioce na home page sajta umesto da fokusirajtu ključne reči na pojedine strane, jer tako će Google dovesti posetioce na stranu koja sadrži upravo ono što oni traže!
Jedan od načina na koji se biraju ključne reči je najpre napraviti listu relevatnih pojmova za sajt,i prema njihovoj hijerarhiji kreirati stablo kljucnih reci kao strukturu koju ćete urediti u odnosu na relaciju < ili > značajan.
Može li Web stranicu zaobići GoogleBot?
Robots.txt fajl sadrži informacije o tome koje stranice ili direktorijume crawler ne treba da indeksira. Inače, on nema nikakvog udela u frekvenciji indeksiranja sajta odnosno tome da li će spider uopšte posetiti sajt.
Kako ući u indeks pretrazivaca, tj. prijaviti sajt na Google?
Najjednostavnije i najefikasnije je ulinkovati novi sajt na neki postojeći koji ima veliki saobracaj i spideri ga redovno obilaze. Na taj način se možete naći u indeksu već za nekoliko dana.
Drugi nacin je program za automatsko prijavljivanje http://www.google.com/addurl.html
Nakon sto je u formular unet URL polazne stranice sajta, spajder Google-a (nazvan GoogleBot) posecuje pojedinacne stranice sajta (3-4 nedelje mu treba) i dodaje ih u Google indeks. Jednom kad je stranica u indeksu, posecuje se od strane sapjdera i obnavlja sadrzaj o njoj.Ipak, nije mudro prijaviti ma koju stranicu na Google. Rang stranice na Googleu biće mnogo veći ako mu prepustite da sam nađe i indeksira Vašu stranicu, jer nema dolaznih veza. Bolje je napraviti mapu stranice koja bi sadržavala linkove na sve podstranice i prijavite je na Google. Jer tada pretraživači će jednostavno pretražiti vaše stranice i sve ih indeksirati.
ŠABLONI ZA OPTIMIZACIJU STRANICE
Google je pretraživač tipa Crawler,
tj. stvara svoje liste za rad automatski na osnovu pretraživanja weba (za razliku od napr. OpenDirectory koji uređuju ljudi uredjivanjem lista po direktorijima i pretragom se gledaju rezultati samo za one stranice koje su prijavljene opisom tj. menjanje izgleda Vaše stranice nema uticaj na to kako je ona rangirana).
No,kod Crawler-a ako promenite svoje web stranice onda puzavica zapravo te promene pronalazi i ažurira svoju bazu podataka. To znači da načinom na koji ste izgradili vaš web site možete značajno uticati na rangiranje na pretraživačkoj listi u Google-u. Naslov dokumenta, opis stranice, zaglavlje, sadržaj dokumenta - sve to igra svoju ulogu pri rangiranju na pretraživačima ovog tipa. OTUDA POSTOJE SAVETI ZA OPTIMIZACIJU STRANICE koji su zavisio od izvornog koda prezentacije i nastali su tako sto su ih delom otkrili ljudi iz Google-a, a delom poticu iz autoratitivnih informatickih izvora i nastali su posmatranjem i razmenom iskustava.
ŠABLONI ZA OPTIMIZACIJU STRANICE
Ključna reč u nazivu domena (URL)
Ključna reč bar u nazivima datoteka
Ključna reč u naslovu stranice blizu početka, ali ne kao prva reč
Ključna reč u tekstu internog linka
Ključne reči u meta-tagovima (gleda se META DESCRIPTION, ako ključne reči ostanu samo u opisu onda su odmažuće, jer je bolje pozicioniran sajt koje ključne reci ima u META tagu i tekstu)
Ispravna koncentracija ključnih reči ( zbog rizika da pretrazivač okarakteriše Web stranicu kao spam - stranicu koja nema odgovarajući sadržaj)
Ključne reči u linkovima (naročito u okviru linka na stranicu ciji PR je >= od 8), podebljane, iskošene; u H1-H3 tagovima; u "alt" opisima
Šabloni za optimizaciju Google Images pretraživanja:
koristiti tradicinalni tag-atribut IMG SRC za sliku, ne koristiti javascript,...
dovoljno deskriptovno ime slike (zeleni-nilski-aligator.jpg)
u imenu slike koristite znak minusa (-) za odvajanje reci, odvojite ključne reci u nazivu slike
postojanje teksta oko slike koji sadrži te ključne reči
po mogućnosti neka se ta ključna reč u imenu slike pojavljuje u title tagu
neka se ta kljucna rec u imenu slike pojavljuje u drugim bitnijim faktorima na stranici
dodati alt tag slici (po mogućnosti kraci opis slike)
sliku više puta pozivati i linkovati sa drugih stranica na sajtu
linkovati sliku i sa drugih sajtova
Optimizovan raspored fajlova po direktorijumima, te optimizacija linkova unutar sajta
Što manje "izlaznih" linkova. Ne preko 100 sa iste stranice. Nikada na rizične stranice (penalizovane, potencijalno banovane i banovane). Penalizovana stranica ima PR jednak 0. Drugi razlog može biti link farming. Link farme se smatraju spamom i dobijaju penale. Zapravo, to su su mini-direktorijumi, stranice sa velikim brojem relevantnih i irelevantnih linkova, po pravilu reciprocitetnih. Postavljaju se sa ciljem povećanja broja dolaznih-linkova i predstavljaju kršenje Terms of Service-a pretraživača. Trebalo bi izbegavati po svaku cenu linkovanje u istima.
Veličina stranice: pretrazivac ne ignorise prvih 20 KB, 40KB,... ali
su problem informacije na preko 100 KB
Ispravan ritam dodavanja stranica i izmena sadržaja
Prednost ima ".edu", zatim ".gov" sajt u razmatranju URLova
Prednost imaju veći sajtovi (npr. jer se lakše šteluju "anchortext" i "Page rank")
Odabrati ključne reči sa optimalnim odnosom između potražnje i konkurencije.
Tekst "dolaznih linkova". Ovo je toliko jak faktor da sajt bez ijednom pomenute kljucne reči može biti prvoplasiran za tu reč
Broj i kvalitet "ulaznih linkova" (čime je praktično obuhvaćen i faktor "Page rank")
Ritam pojavljivanja "ulaznih linkova" (kada liči na veštački, biva sankcionisan): "ulazni linkovi" treba da su što bliže početku stranice (te na kojoj su, naravno) u ti na sajtu što većeg značaja i ranga
Google meri čak i promet prema sajtu, i procenat odabiranja istog
Pominjanje sajta na usenet-u i na sličnim mestima
ŠABLONI SA LOŠIM UTICAJEM
Skrivanje teksta (STARI TRIK) ili skriveni linkove na stranici - npr. ista boja teksta kao boja pozadine. Ovo se penalizuje oštro, ali moze da se prevari google upotrebom spoljašnjeg css fajla koji moze da skriva tekst. No, uvek može neki posetilac da Vas prijavi GoogleSpamReport-u
Gomilanje naslova (postavka većeg broja kopija title taga na jednoj stranici) - STARI TRIK
Prikaz jedne stranice pretraživaču, a druge posetiocima (identifikovanjem UserAgent niske ili IP adrese moze da se jedna stranica prikaze posetiocu, a druga spideru) . Ne koristite cloaking skript i redirekte(javascript redirekcije) - cloaking je skript koji prepoznaje GoogleBotove, te njima servira razlicitu stranicu nego korisniku.
Postavljanje irelevantnih ključnih reči u META tag (bez prisustva na stranici!!!)
Odsustvo reči (time i ključnih reči), npr. kad je tekst smešten unutar slika ili fleš animacije
Problem moze biti preterano koriscenje javaskripta ili koriscenje javaskripta u vaznim delovima Web sajta poput navigacije, zatim koriscenje cookiesa, session promenljive (problem: cesto menjaju izgled URLa), frameova, DHTML ili flasha. Resenje je ne koristite te tehnologije ukoliko one nisu stvarno nuzne. Ukoliko imate sajt u flashu, napraviti i obicnu HTML verziju samih stranica. Ukoliko zelite padajuci meni, koristite CSS, a ne javaskript
Pomenuti "izlazni linkovi" koji vode na sumnjive sajtove, takođe: preterana izlinkovanost dva ili više sajtova
Pravopisne greške, psovke
Povrede copyright-a. Ovo mašina ne prepoznaje lako, ali drugi korisnici mogu da prijave Google spam report-u
Izmene teksta u linkovima, a nipošto u imenima html fajlova
Izmena teme stranice
Neprecizno fokusiranje ključne reči i teme stranice
Prijava od strane posetioca da postoji "trampa" linkova sa tematski nepovezanim sajtovima
Kupovina (ulaznih) linkova prepoznata kao pokušaj manipulacije
Nula "ulaznih linkova"
Gomilanje "ulaznih linkova" na forumima ili knjigama gostiju
Povremena nedostupnost servera
=================================================================================
SIGURNOST GOOGLE-a
Veličina naslovne stranice Google limitirana je na par stotina bajtova i tačno 37 reči – kada imate milione korisnika, svaki dodatni bajt predstavlja rizik da pretraga postane sporija a internet link zagušeniji. Google i dalje ima samo jedan bazičan servis, pretraživanje interneta, i ne želi da na svoju naslovnu stranu dodaje sadržaje koji će sputavati korisnike sa skromnijim hardverom.
Još jedna zanimljivost u vezi Google-a je i sigurnost njihovih stranica. Naime, otkad postoji Google, hackeri su uspeli srušiti samo jednu Google stranicu, tj. Picasa, softver za organizovanje digitalnih fotografija.
Svoj renome najbrže mašine za pretraživanje Google u velikoj meri duguje svojoj hardverskoj infrastrukturi. Google osnivačisu vrlo rano zaključili da ukoliko svoju računarsku mrežu budu zasnovali na skupim serverima najvećih svetskih proizvođača, postoji realna opasnost da bankrotiraju usled ogromnih troškova. Umesto toga, opredelili su se za kupovinu velikog broja jeftinih, identičnih servera, zasnovanih na Intel procesorima i pouzdanim tvrdim diskovima iz ekonomske klase. Na ovaj hardver dolazi operativni sistem Linux, Google softver koji povezuje servere u jednu inteligentnu celinu i gigabitni internet link. Google je razvio sopstveni sistem za balansiranje opterećenja mreže tako da se svaki novi zahtev za pretragu upućuje serveru čije je opterećenje najmanje. Sistem je visoko redundantan: ako otkaže jedan disk u serveru, njegovu ulogu transparentno će preuzeti drugi disk. Ako otkaže čitav server, njegovu ulogu preuzeće susedni server u istom klasteru (grupi). Googlel ima rešenje i za slučaj da otkaže čitav klaster.
Google servera trenutno ima oko deset hiljada računara, a njihov broj se svakoga dana uveća za oko trideset. Svi serveri su identično konfigurisani tako da je servisiranje i proširenje mreže veoma pojednostavljeno. Ukupna količina arhiviranih informacija meri se terabajtima, a glavna baza podataka raspodeljena je na nekih 10.000 diskova. Kada mreža raste tempom od 25 odsto mesečno, fizički smeštaj uređaja počinje da predstavlja problem: Google od svojih dobavljača hardvera insistira na kompaktnom dizajnu jer po kompanijskim standardima u prostor veličine jednog kubnog metra mora da stane bar 80 servera.
=======================================================================
IMA LI SMISLA RAZVIJATI U DANASNJEM DOBU IR ALATE KOJI NE LICI NA GOOGLE?
Gotovo nezapaženo prošao je nedavno objavljen podatak da se čitavih 95% svih pretraga na američkom Webu obavlja preko samo dve kompanije - Google i Yahoo - što direktno, putem pretraživačkih servisa koje poseduju, što indirektno, putem sajtova koji upotrebljavaju njihove tehnologije. Samo Google u svojoj bazi drži preko 4,2 milijarde indeksiranih web stranica i nju prilikom pretraživanja dnevno konsultuje oko 200 miliona posetilaca. Taj podatak jasno ukazuje na to koliki uticaj Google ima na online ponašanja ljudi
Ipak, tekuci Web pruža priliku manjim pretraživačima, koji se sve češće fokusiraju na oblasti koje "veličine" poput Googlea ili Yahooa ne mogu adekvatno da pokriju - lokalne i tematski usko specijalizovane informacije.
Primer pretraživača "novog kova" su tzv. faceted browseri, koje krase karakteristike poput specijalizovanosti za pojedine tematske celine, vizuelno predstavljanje rezultata upita, odsustvo hijerarhije i mogućnost višeslojnog, odnosno horizontalnog kretanja kroz sadržaje koji se nalaze u njihovim bazama.
Faceted browsing definiše se kroz način na koji se odvija interakcija između korisnika i pretraživača. Do željenih rezultata dolazi se u nekoliko progresivnih koraka, u kojima korisnik klikovima filtrira (precizira) sadržaj i na taj način stiže do sve preciznijih i preciznijih logičkih celina. Tokom procesa "prosejavanja" sadržaja, on nije u obavezi poštovanja posebnog redosleda ili hijerarhije i može se logički kretati u više različitih smerova. Jednostavno, reč je o pretraživanju po bazi zasnovanom na logičkim vezama između njenih elemenata, koje je vremenski nešto zahtevnije ali efektnije od tradicionalnog "uredi i pretraži " načina.
Pretraživači umetničkih dela
Na primer,pretraživača novog doba jeste Flamenco (http://bailando.sims.berkeley.edu/flamenco.html), koji je specijalizovan za oblast lepih umetnosti i arhitekture i problemu traženja umetničkih sadržaja pristupa na sofisticiraniji način, nalik šetnji po muzeju ili galeriji. U njegovoj bazi nalazi se kolekcija od preko 35.000 digitalizovanih slika umetničkih predmeta koji se nalaze u fundusu Muzeja lepih umetnosti u San Francisku, Legije časti (Legion of Honor) i Muzeja de Young, identifikovanih tekstualnim opisima, kao i slike mnogobrojnih arhitektonskih dela lociranih širom sveta. Slike predmeta, odnosno građevina, klasifikuju se u preko deset kategorija, kao što su medijum (platno, skulptura, nameštaj...), vreme nastanka, autor dela ili sadržaj (cveće, životinje, portret...).
=================================================================================
ANALIZA HIPERVEZA
Otkrivanje strukture veza na Web-u nastoji da otkrije fundamentalni model strukture linkova na Web-u. Model mora biti zasnovan na topologiji hiperlinkova sa ili bez opisa linkova. Ovaj model može biti korišćen za kategorizaciju Web strana, a koristan je i za generalizaciju informacija, kao što su sličnosti i veze između različitih Web sajtstova , kao i za otkrivanje autorizovanih sajtova.
U pristupu zasnovanom na bazama podataka, predmet interesovanja je struktura unutar Web dokumenata (intra-dokumentna struktura i struktura hiperlinkova unutar samog Web-a (inter-dokumentna struktura). Ova oblast istraživanja je inspirisana analizama društvenih mreža i analizama citata (study of social networks and citation analysis) . Pomoću analiza društvenih aspekata mreža možemo otkriti specifične vrste Web strana koje se zasnivaju na ulaznim i izlaznim linkovima (“incoming and outgoing links”). Pri tom se koristi strukture hiperlinkova na Web-u da bi primenio analize društvenih mreža na model osnovne strukture linkova na samom Web-u.
Predloženi su neki algoritmi za modeliranje topologije Web-a, kao na primer: HITS , PageRank, i poboljšanje HITS-a zasnovano na dodavanju informacionog sadržaja strukturama linkova. Ovi algoritmi se uglavnom primenjuju kao metode za utvrđivanje kvalitetnih delova ili važnih činjenica svake Web strane.
==============================================================================
META - INFORMACIJE PRETRAŽIVAČA: LOG ANALIZA
Otkrivanje obrazaca u korišćenju Web-a pokušava da da smisao podacima generisanim u Web korisničkim sesijama, ili podacima o ponašanju korisnika. Dok prethodno pomenuta analiza hiperveza koriste realne i primarne podatke na Web-u, log analiza otkriva sekundarne podatke izvedene iz interakcija korisnika u toku njihovog rada na Web-u. Ova oblast koristi podatke iz pristupnih logova Web servera, logova proksi servera, logova pretraživača, korisničkih profila, registracionih podataka, korisničkih sesija ili transakcija, korisničkih upita, pokretanja ili pritiskanja tastera miša, i bilo koje druge podatke koji nastaju kao rezultat interakcije korisnika
Log analiza predstavlja automatizovano otkrivanje obrazaca u korisničkim pristupima Web serverima.Organizacije prilikom obavljanja svakodnevnih operacija prikupljaju ogromne količine podataka koje Web serveri automatski generišu i prikupljaju u logovima za pristup serveru. Druge izvore korisničkih informacija predstavljaju referencirani logovi (“referrer logs”) koji sadrže informacije o referenciranim stranama za svaku referencu na strani, zatim informacije o registraciji korisnika ili pregledu prikupljenih podataka preko CGI skripta.
OTKRIVANJE OBRAZACA U WEB TRANSAKCIJAMA
Zbog mnogih jedinstvenih karakteristika modela klijent – server, različitosti fizičkih topologija Web skladišta, razlike između korisničkih pristupnih putanja i razlike u jedinstvenoj identifikaciji korisnika postoji mnoštvo zadataka u predprocesiranju podataka koji moraju biti završeni pre nego što se algoritmi za otkrivanje obrazaca pokrenu.
Ovo zahteva razvoj modela podataka unutar pristupnih logova, razvoj tehnika za prečišćavanje/ filtriranje podataka u cilju eliminisanja izuzetaka ili irelevantnih podataka, grupisanje pojedinačnih Web strana u semantičke jedinice (tj. transakcije), integraciju različitih izvora podataka i razvoj generičkog algoritma koji bi bio prilagođen specifičnoj prirodi podataka u logovima za pristup Internetu.
ZADACI PREDPROCESIRANJA
Prvi zadatak predprocesiranja je prečišćavanje podataka. Tehnike prečišćavanja logova servera u cilju eliminacije irelevantnih podataka su od velikog značaja za sve vrste Web log analiza. Otkrivene asocijacije ili statističke zavisnosti su korisne jedino ako podaci koji se nalaze u logovima servera daju odgovarajuću sliku korisničkih pristupa Web sajtu. Eliminisanje irelevantnih podataka može biti veoma uspešno izvršeno proveravanjem sufiksa URL naziva.
U vezi s tim je i mnogo teži problem određivanja veoma važnih pristupa serveru koji nisu snimljeni u pristupnom logu. Mehanizmi kao što su lokalno keširanje i “proxy” serveri mogu ozbiljno iskriviti globalnu sliku korisničkih putanja kroz Web sajtove. Odgovarajući mehanizmi za savladavanje ovog problema koriste “cookie” fajlove i eksplicitne registracije korisnika. Međutim, “cookie” fajl može biti obrisan od strane korisnika, dok je registracija korisnika dobrovoljna, pa korisnici često daju netačne informacije. Zadovoljavajuće rezultate daju metode za rad sa problemima keširanja koje koriste topologiju sajtova ili referenciranih logova zajedno sa privremenim informacijama u cilju pronalaženja nedostajućih referenci.
Drugi problem sa “proxy” serverima je identifikacija korisnika. RAZLOG: Korišćenje imena mašine za jedinstvenu identifikaciju korisnika može prouzrokovati da se nekoliko korisnika pogrešno grupiše kao jedan korisnik.
Ako zahtevana Web strana nije direktno povezana sa prethodnom stranom, sigurno je da na toj mašini postoje višestruki korisnici. U drugim algoritmima se za identifikaciju korisnika koristi automatski određena dužina korisničkih sesija zasnovana na navigaciji obrasca. Ostale heuristike obuhvataju korišćenje kombinacija IP adresa, imena mašina, agenata pretraživača, kao i privremenih informacija za identifikaciju korisnika.
Drugi, glavni, zadatak predprocesiranja je identifikacija transakcija. Pre nego što se izvrši bilo kakvo otkrivanje korisnih podataka na Web-u nizovi referenciranih Web stranica moraju biti grupisani u logičke jedinice koje predstavljaju Web transakcije i korisničke sesije.
Korisničku sesiju čine sve Web stranice koje je korisnik posetio za vreme posete sajtu. Identifikacija korisničkih sesija je problem sličan problemu identifikacije individualnih korisnika koji je prethodno opisan. Veza između transakcije i korisničke sesije je to što transakcija obuhvata jednu ili više referenciranih strana u korisničkoj sesiji. Broj strana u transakciji zavisi od korišćenog kriterijuma za identifikaciju transakcije. Nasuprot tradicionalnim velikim bazama podataka o prodaji, konvencionalna metoda za klasterizaciju referenciranih Web stranica unutar transakcije manje od jedne cele korisničke sesije ne postoji.
TEHNIKE OTKRIVANJA OBRAZACA U WEB TRANSAKCIJAMA
klaster analiza
analize putanja
otkrivanja asocijativnih pravila
otkrivanja sekvencijalnih obrazaca
otkrivanje klasifikacionih pravila
Klaster analiza otkriva grupe klijenata, ili podatke o članovima koji imaju slične karakteristike. Klasterizacija informacija o klijentima, ili podataka o članovima, u logovima transakcija na Web-u, može olakšati razvoj buduće strategije, bilo on-line ili off-line, kao što je dinamičko menjanje pojedinih sajtova za klijente, na osnovu prethodno izvršene klasifikacije podataka datog klijenta.
Postoji mnogo različitih vrsta grafova koji mogu biti formirani za izvođenje analize putanja (“path analysis”), pošto grafovi najbolje reprezentuju neke relacije definisane na Web stranicama (ili drugim objektima). Najznačajnije je to što graf reprezentuje fizički raspored Web sajtova, sa Web stranama kao čvorovima i hipertekst linkovima između strana kao granama. Neki grafovi mogu biti formirani na osnovu tipova Web strana, sa granama koje predstavljaju sličnost između strana, ili kreiranjem grana koje daju broj korisnika koji prelaze sa jedne Web strane na drugu.
Mnoštvo radova obuhvata određivanje patterna čestih prelazaka sa sajta na sajt, ili velikih sekvenci referenci na sajtove, kroz fizički raspored unutar grafa. Analiza putanja može biti korišćena za određivanje najfrekventnije posećenih putanja na Web sajtu. Analizom putanja direktno mogu biti otkriveni razni primeri korisnih informacija, kao što su, na primer:
Prvo pravilo pokazuje da postoje korisne informacije unutar /company/product2/, ali pošto korisnici idu kružnom putanjom do te strane, ona očigledno nije jasno obeležena. Drugo pravilo jednostavno pokazuje da je prilikom posete sajta cilj korisnika poseta druge strane (/company/products/), a ne glavne (koju u ovom primeru predstavlja strana /company/), što može biti dobra ideja za uključivanje glavnih informacija na ovoj strani, ukoliko se već ne nalaze na njoj. Poslednje pravilo ukazuje da pošto mnogo korisnika ne posećuje više od četiri strane na sajtu, treba biti obzriv i osigurati da se sve važne informacije nalaze unutar četiri strane ulaznih referenci zajedničkog sajta.
Uopšteno rečeno, tehnike otkrivanja asocijativnih pravila se primenjuju nad bazama podataka o transakcijama, gde se svaka transakcija sastoji od skupa članova. U tom kontekstu, problem se sastoji u otkrivanju asocijacija i korelacija između podataka o članovima transakcija, gde prisustvo jednog skupa članova u transakciji implicira prisustvo drugih članova. U kontekstu otkrivanja obrazaca , ovaj problem je istovetan problemu otkrivanja korelacija između referenci na različite fajlove raspoložive korisnicima servera. Svaka transakcija obuhvata skup URL-ova kojima je korisnik pristupio prilikom jedne posete serveru. Na primer, korišćenjem tehnika otkrivanja asocijativnih pravila možemo naći korelaciju kao što je sledeća:
Pošto obično takva baza podataka o transakcijama sadrži ekstremno veliki skup podataka, odgovarajuće tehnike otkrivanja asocijativnih pravila pokušavaju da smanje istraživački prostor, da bi obezbedile podršku za članove koje je neophodno uzeti u obzir prilikom razmatranja. Podrška je mera zasnovana na broju slučajeva korisničkih transakcija unutar logova servera.
Problem otkrivanja sekvencijalnih obrazaca se sastoji u nalaženju obrazaca između transakcija, ali tako što je prisustvo u skupu članova određeno vremenskim obeležjima skupa transakcija. U logovima transakcija Web servera posete klijenata se snimaju po vremenskim periodima. Vremensko obeležje dodeljeno transakciji u ovom slučaju može biti vremenski interval koji je determinisan i vezan za transakciju tokom predprocesiranja podataka, ili tokom procesa identifikacije transakcije. Analizom ovakvih informacija, IR sistem može odrediti privremene veze između podataka kao što su sledeće:
Druga važna vrsta zavisnosti između podataka koja može biti otkrivena korišćenjem privremenih karakteristika podataka je vremenski redosled. Na primer, može nas interesovati nalaženje zajedničkih karakteristika klijenata koji su posetili pojedini fajl u toku vremenskog perioda [t1,t2]. Ili, suprotno, može nas interesovati vremenski interval (na primer, tokom dana, ili tokom nedelje) u kome je pojedini fajl najposećeniji.
Otkrivanje klasifikacionih pravila omogućava razvoj profila članova koji pripadaju pojedinim grupama, na osnovu njihovih zajedničkih atributa. Ovaj profil može kasnije biti korišćen za klasifikaciju novih podataka članova koji se dodaju u bazu podatka. Tehnike klasifikacije omogućavaju razvoj profila korisnika koji posećuju pojedine fajlove na serveru, zasnovanog na demografskim informacijama raspoloživim o datom klijentu, ili zasnovanog na obrascima u pristupima Web serveru. Na primer, klasifikacija pristupnih logova WWW-u može voditi otkrivanju veza kao što su sledeće:
===================================================================================
ELIMINACIJA DUPLIKATA U REZULTATIMA PRETRAGE
je filter u vecini danasnjih pretrazivaca koji iz rezultata pretrage eliminise različite stranice ili linkove sa istim ili vrlo sličnim sadržajem.
PRIMER: Web sajt koji ima naslovnu stranicu stranicu sa spiskom 100 proizvoda i svaki proizvod ima svoju stranicu, 100 stranica, pa recimo imate i print verziju tih 100 stranica, tj. isti sadržaj na dva različita linka. U tom slučaju bi tih 200 stranica bilo indeksirano. Ali svakako ih kasnije treba isključeni iz glavnog indeksa i pretraživanja ili poslati u pomocni pridruzen indeks. Kako iz rezultatima pretraživanja odstraniti linkove sa istim sadržajem, odnosno na temelju kojih faktora izabrati koji je od ta dva linka bolji.Google negativne posledice po stranicu koja je eliminisana u pomocni indeks
Gubitak u posecenosti sa stranica koje je eliminisao filter, stranice koje nisu u glavnom indeksu mogu se naci u fazi pretrazivanja jedino na vrlo specificne fraze, na pretrazivanja pod navodnicima ili koristeci specificne Googleove operatore pri pretrazivanju.
RESENJE
Resenje je naravno razliciti sadrzaj na svim stranicama. Pretrazivaci su u mogucnosti potpuno shvatiti strukturu stranica, gde se tacno nalazi navigacija, sadrzaj, footer stranice, linkovi, i u stanju su iskljuciti te komponente i ostaviti samo sadrzaj i uporediti sa drugih vasim linkovima i dobit tacnu predstavu da li je sadrzaj jedinstven na nekoj stranici.
Dva faktora koja igraju veliku ulogu su title tag i meta description tag.
Za title tag je Google sam objavio na svojim stranicama da igra veliku ulogu u ovom slucaju, dok je meta description iz iskustva mnogih. Svaka stranica mora imati drugaciji title tag, drugaciji meta description tag i barem paragraf unikatnog sadrzaja. Naravno mozete i u drugim bitnijim faktorima dati do znanja da se radi o drugoj stranici, npr. kroz navigaciju, kroz naslove (h1).
Tesko je odrediti gde je granica koliko je potrebno unikatnog sadrzaja na stranicama da ne upadne u filter, no to ne bi trebalo zabrinjavati. Ukoliko stranice upadnu u filter znaci da morate dodati jos sadrzaja na njih.
Print verzije dokumenata:
Preporuka Google-a je da se print verzije blokiraju jer tvrde da ih to zbunjuje u odabiru najbolje stranice koje ce uvrstiti u pretrazivanje. Ukoliko se ne blokiraju, moguce je, da se u pratrazivanju pojavljuje print verzija umesto linka kojeg ste zeleli.
ALGORITMI ZA PREPOZNAVANJE DUPLIKATA
DVE STRATEGIJE
1. Pronalazak slicnih Web dokumenata
2. Pronalazak duplih domena (mirrors)
Pronalazak slicnih Web dokumenata (D1, D2 su dva dokumenta, S1, S2 su njihovi uzorci - metodom obrazaca,...)
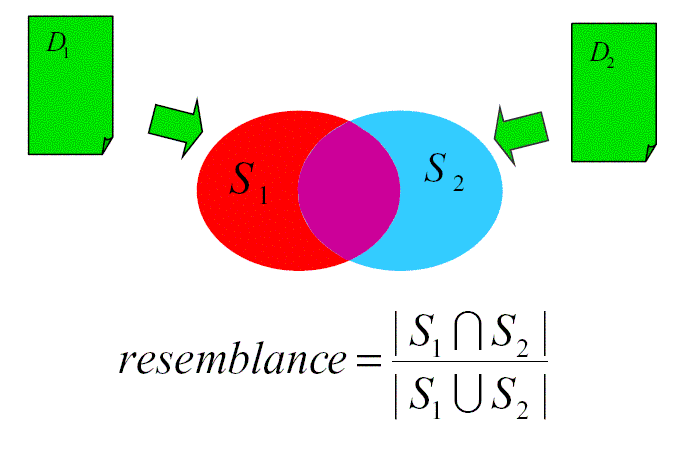
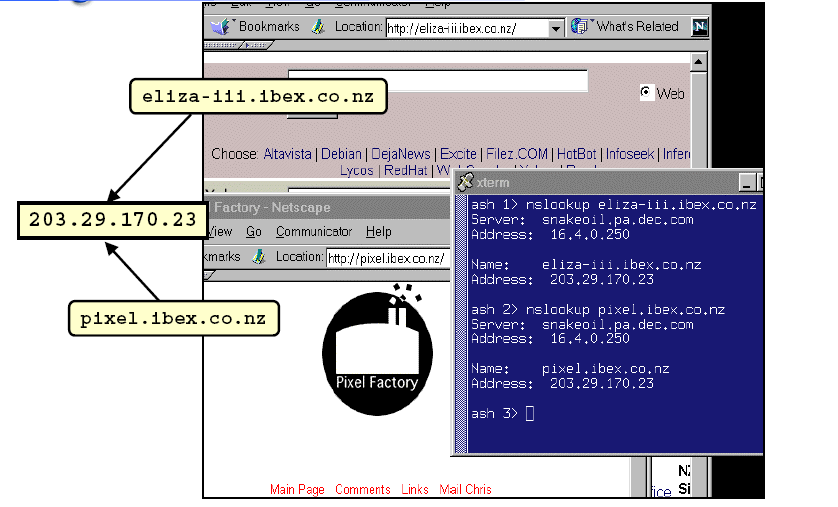
DEFINICIJA:
Host1 and Host2 are mirrors <=>
For all paths p such that http://Host1/p is a web page, http://Host2/p exists with duplicate (or near-duplicate) content, and vice versa.

Načini određivanja klastera
Algoritmi za određivanje klastera podataka mogu biti hijerarhijski ili particionalni. Upotrebom hijerarhijskih algoritama neprekinute grupe se pronalaze upotrebom pređašnjih uspostavljenih grupa, tj. onde gde particionalni algoritmi određuju sve grupe u jednom hodu. Hijerarhijski algoritmi mogu biti aglomerativni (dnom prema gore) ili divizivni (vrhom prema dole). Aglomerativni algoritmi počinju sa svakim elementom kao odvojenom grupom te ih spajaju u neprekinuto velike grupe. Divizivni algoritmi počinju s čitavim skupom i nastavljaju ga deliti u neprekinuto malene grupe.
Hijerarhijsko klasterovanje gradi (aglomeracijski) ili prekida (divizivno) hijerarhiju grupa. Tradicionalni prikaz ove hijerarhije je stablo s individualnim elementima na jednom te pojedinačnom grupom sa svim elementima na drugom kraju. Aglomeracijski algoritmi počinju na vrhu stabla, dok divizivni algoritmi počinju na njegovom dnu. (Na slici 1 strelice označavaju aglomeracijsko klasterovanje.)
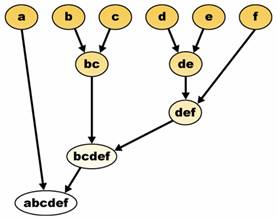
Slika 1
Sečenjem stabla na danoj visini daje klasterovanje u odabranoj preciznosti. U gornjem primeru sečenje daje nakon drugog reda grupe {a} {b c} {d e} {f}. Sečenje nakon trećeg reda daje grupe {a} {b c} {d e f}, što je zapravo grubo grupiranje s manjim brojem većih grupa.
Tipičan predstavnik ove grupe je algoritam k-sredine koji se ne može primeniti na nenumeričke atribute, ali se njegoom modifikacijom dobijaju particioni algoritmi koji se danas primenjuju na kategorijskim podacima. No, ulazni parametra algoritma je broj klastera k. Ako je broj grupa K u metodi pogrešno odabran, konačni rezultati neće biti dobri. Ispravan pristup odabiru broja klastera bio bi da se eksperimentira s različitim brojem klastera. Postoje algoritmi koji ine zahtevaju zadavanje broja klastera pre primene algoritma.
Algoritam k-sredine dodeljuje svaku tačku grupi čiji je centar (ili centroid) najbliži. Centroid je tačka stvorena računanjem aritmetičke sredine za svaku dimenziju odvojeno za sve tačke u grupi.
Ovo je osnovna struktura algoritma (J. MacQueen, 1967.):
Glavne prednosti ovog algoritma su njegova jednostavnost i brzina koja mu dopušta primenu na velikim skupovima podataka. Ali, rezultirajući klasteri zavise od početnih dodeljivanjima. Algoritam k-sredina pojačava (ili smanjuje) različitost međugrupa, ali ne osigurava da dobijeno rešenje nije lokalni minimum različitosti.
QT Clust (Heyer et al, 1999.) je alternativna metoda određivanja klastera podataka koja ne zahteva zadavanje broja grupa unapred. Prvo se gradi kandidatna grupa za svaku kao i za pojedinu tačku uključivanjem najbliže tačke, sledeće najbliže, i tako dalje, sve dok se ne dosegne prag udaljenosti. Udaljenost između tačke i grupe tačaka se izračunava upotrebom potpune povezanosti, tj. kao najveća udaljenost od tačke do svih članova grupe. Kandidatna grupa s najviše tačaka se sprema kao prva prava grupa, a sve se tačke u grupi uklanjaju iz daljnjeg razmatranja. Algoritam ponovo susreće, ponavljajući proces s reduciranim skupom tačaka podataka.
Jedan od problema algoritma k-sredina je da daje grubo razdeljivanje podataka, tj. svaka je tačka pridodana jednoj i samo jednoj grupi. Ali tačaka na rubu grupe ili blizu druge grupe ne mora biti jednako mnogo u grupi kao tačaka u središtu grupe.
Stoga u raspršenom određivanju klastera svaka se tačka ne zadržava u danoj grupi, ali ima stepen pripadnosti određenoj grupi kao i u difuzivnoj logici. Za svaku točku x postoji koeficijent koji daje stepen pripadnosti k-toj grupi uk(x). Obično zbir tih koeficijenata mora biti jedan tako da uk(x) označuje verovatnoću pripadanja određenoj grupi:
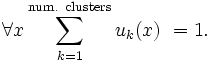
Sa raspršenim c-sredinama centroid grupe se izračunava kao sredina svih točaka s težinom na njihovom stupnju pripadnosti grupi, to jest
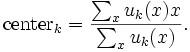
Stepen pripadnosti određenoj grupi je obrnut udaljenosti od grupe
![]()
Onda se koeficijenti normaliziraju i zapliću s realnim parametrom m > 1 tako da je njihov zbir 1. Dakle 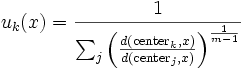
Algoritam raspršenih c-sredine je uveliko sličan algoritmu k-sredina; kada je ![]() , algoritmi su jednaki:
, algoritmi su jednaki:
Algoritam raspršenih c-sredina jednako smanjuje međugrupnu različitost, ali ima iste probleme kao k-sredine, minimum je lokalni minimum, a rezultati zavise od početnih odabira težina.